Application Features
- Synchronisation :
- Multiple remote protocols (ftp, sftp, http, local copy, rsync, irods…)
- Data transfers integrity check
- Release versioning using a incremental approach
- Multi threading
- Compatible with a Galaxy server
- Data extraction (gzip, tar, bzip)
- Data tree directory normalisation
- Custom listing/download with plugins
- Pre &Post processing :
- Advanced workflow description (D.A.G) using Easy normalized syntax language
- Post-process indexation for various bioinformatics software (blast, srs, fastacmd, readseq, etc…)
- Easy integration of personal scripts for bank post-processing automation
- DRMAA cluster integration
- Compatible with Conda (https://bioconda.github.io/)
- Supervision :
- Administration web interface (biomaj-watcher)
- Web access to logs
- Click / Cron management of updates
- CLI status
- Prometheus and Influxdb optional statistics
- Administration web interface (biomaj-watcher)
- Repository statistics
- Mail alerts for the update cycle supervision
- Search in available formats/types/tags/files (indexation)
News/more informations here.
More informations about BioMAJ management and metrics here.
BioMAJ way to work
BioMAJ has two modes of running, it could be a monolithic application or be abble to work with microservices.
Standalone version of BioMAJ
In this case, BioMAJ is usable/callable in a mode for single server or local usage.
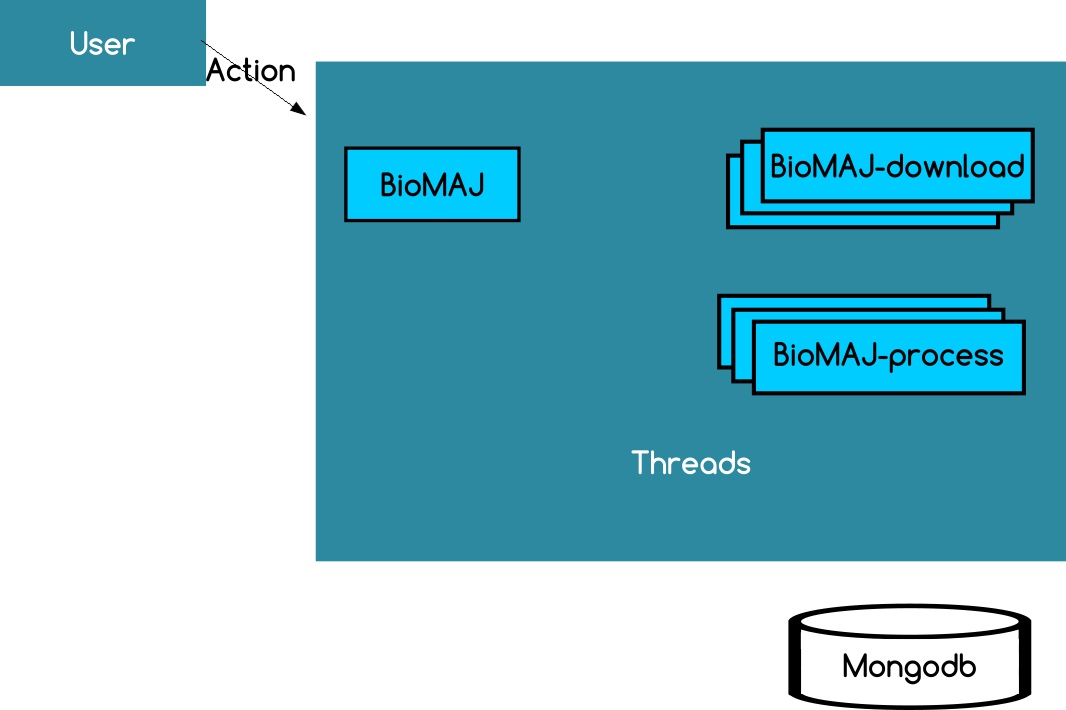
Execution
- Each workflow is executed in parallel on the server where BioMAJ is installed (execution, download, processes)
- If an update is in progress, it is not possible to do the same update in the same time
- Command-line tool execute banks operation on local server
- The workflow is executed with the privileges of the user who executed the update command.
- Database and configuration files are readable by any user having access to the server.
BioMAJ-download: Downloaders
- Number of thread defined per bank for parallel downloads
- It is possible to connect to a remote server (root access via: ftp://my.server.org/root/subdir)
- The remote server is scanned using regexp, which allows you to save the location of the files, the last modification date, the size, etc.
- Files are uploaded in parallel to the offline directory in the offline-dir directory
- If no release is defined in the bank file, the release will correspond to the most recently updated file.
- It is possible to limit the number of parallel downloads via files. num. thread.
Release checks
The workflow checks the release information, if there is already the same release in the database, the workflow stops (unless it is forced). If there is a new release, the release information will be recorded.
Process handlers
- The process manager handles their execution sequentially or in parallel
- The processes correspond to a tool executable associated with arguments
- The processes must return an exit code of 0 otherwise they are considered to be in failure.
- Per process logs are recorded in bank log directory
- Multiple execution environments are available (local, docker, drmaa)
Microservices version of BioMAJ
If BioMAJ is deployed in microservices mode, all components can be scaled independently to face the load/updates (and be based on Docker or not).
For example, it is possible to launch 3 instances of the download component to handle, at maximum 3 parrallel downloads, whatever the number of banks being updated at the same time. All updates will share the same download components, and waiting downloads will simply be queued and dispatched to the components. At any time, components can be scaled up or down with automatic registration.
BioMAJ client can also request update/status etc.. from a remote server with his credentials.
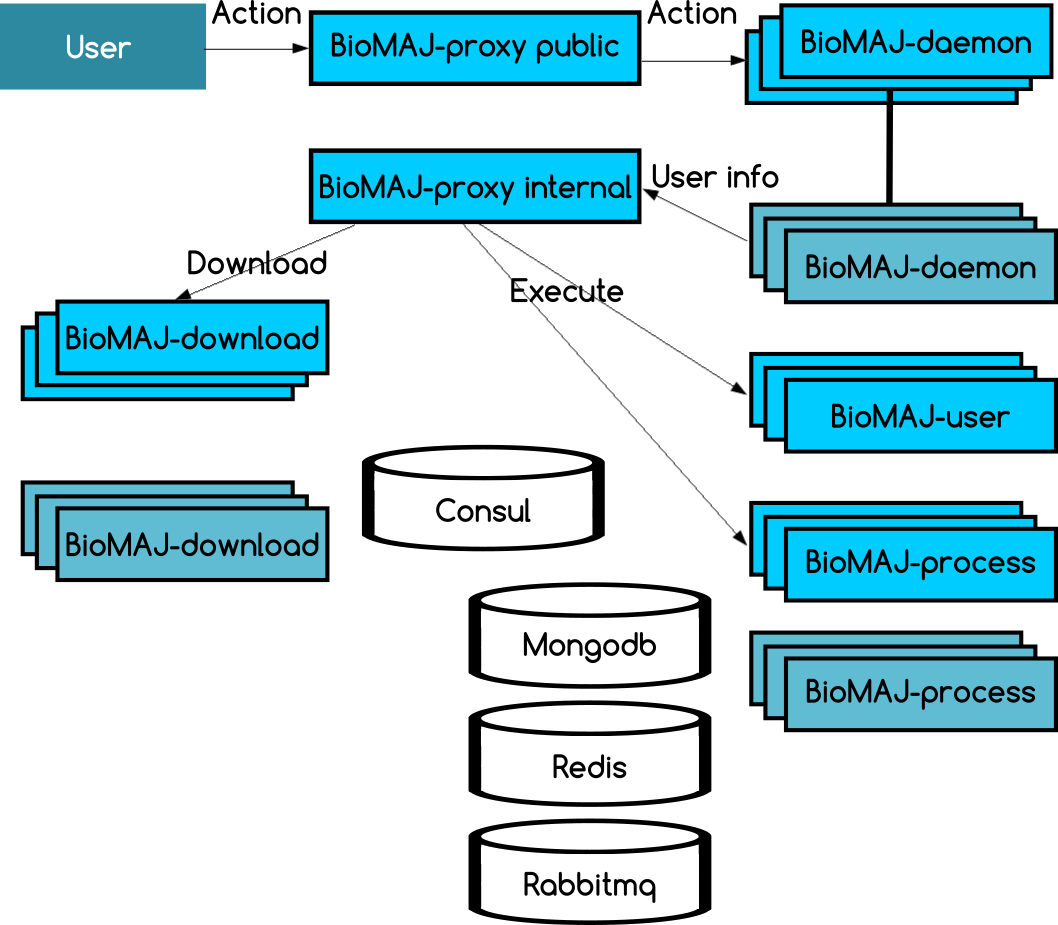
Each service:
- runs independently, possibly on different servers
- communicate via different channels (redis queues, rabbitmq messaging)
- can be scaled
How to interact with the client?
The client (biomaj-cli) is installed anywhere and communicates with public-proxy (the only component that absolutely must be public, others can remain private). Biomaj users each have a profile associated with an API-Key (created by an administrator thanks to the biomaj-user service). All interactions made with the client go through the public-proxy via the API (it is also possible to interact with biomaj directly via the API).
Specifically, the client interacts with public proxy via the API (it is possible to speak with BioMAJ directly via the API). The other services talk to each other using private-proxy (by internal API or message).
API Documentation: Here.
Proxies – service discovery
- Each service register itself to Consul service with health-checks
- Private and public proxies question Consul to obtain a list of available services and to balance the loads among available services according to the type of service requested.
- For messaging, rabbitmq load balance messages among service listeners. In case of
failure, message is resent to an other available service.
Execution
- Different workflows can run in parallel to manage the execution of updates in parallel.
- It is not possible to make a new request on a bank being downloaded (it will be rejected)
- Operations on banks are queued and handled by the different daemon services.
- Each daemon is in charge of one workflow at a time (bank update, removal, etc.)
- Daemon sends operations to download and process handlers when needed and wait for their completion. During the completion time, workflow is paused but resources are not released.
BioMAJ-download: Downloaders
- Download manager sends download requests to the instance of BioMAJ-download
- One instance takes care of downloading one and only one file
- List of files to download is queued and processed by the different BioMAJ-download instances
- It is possible to limit the number of parallel downloads via files. num. thread.
Process handlers
- Process manager sends execution requests to BioMAJ-process instances.
- One instance takes care of executing one and only one process
- List of programs to execute is queued and processed by the different handler instances.
What are the web service and the message service?
Download and Process instances are managed via 2 components:
- xx-web
- xx-message
The web service manages sessions with the workflow manager. There should be one web service per message service to handle load nicely.
The message service will receive requests per download/process requests, while the web service will inform workflow manager of the overall progress.